Exploring Lookalike
- by Shashank and Ritika
"Instagram tries to understand what you like and keeps giving you that. Sometimes it throws in new content to see if you like it, but mostly it sticks to what you've liked in the past."
It's a neat trick, but it works best for active users. What about the folks who are new or just haven't interacted enough? Those are the cold and sparse users."
The Challenge of Cold and Sparse Users
Recommendation systems typically consist of three components: a) User pool, b) Item pool, and c) Interactions.These systems recommend items to users based on their past interactions. However, for cold and sparse users who lack sufficient interaction data, traditional recommendation systems struggle to make accurate predictions.
Enter Lookalike Modeling. It finds users with similar behaviors and preferences to predict content that new or less active users might enjoy. Kinda like when you meet someone new and realize they have similar tastes and interests as your best friend. This approach is based on two hypotheses:
- Users can be grouped by shared characteristics.
- Users within a group react similarly to certain treatments.
If these hypotheses hold true, we can identify dense (active) users similar to cold-sparse users, apply the treatments used for dense users, and expect increased engagement from sparse users.
Step 1 - Analysis
For those new to recommender systems, follow the guide to recommender systems in production. Before deploying a lookalike model, thorough analysis is necessary:
- Fetch and clean user metadata for our dense users.
- Cluster the user metadata.
- What algorithm to choose here? Start simple with k-means.
- How many clusters to choose?
- Analyze the clusters.
- Identify and evaluate the user personas coming out of the clusters.
- Correlate with the user behavior.
- Within a cluster, the behavior should be similar; across the clusters, the behavior should be different.
- How to define behavior? Let's call it how they react to content, and quantize it somehow.
Once the analysis comes through we have a good amount of confidence in the methodology, until hypothesis one. We will cover some key waypoints along the way.
User Metadata
User metadata includes demographic information, device specifications, and category preferences:
- Demographic Information: Gender, city tier.
- Device Specifications: Phone price, screen DPI.
These helped in providing insights into the user's geographical location and potentially socio-economic status.
- Category Preferences: An 18-dimensional vector from onboarding, where each dimension corresponds to preference along a specific content category.
Feature Engineering
- Derived Features: Gender is a derived feature inferred from other features.
- One-Hot Encoding: Convert categorical variables.
- Normalization: Scale continuous variables.
Dimensionality Reduction and Clustering
Use Singular Value Decomposition (SVD) for dimensionality reduction. Employ the elbow method for K-means to determine the optimal number of clusters.
Keep in mind all of these simple first steps. Each step can be individually iterated upon to gain disproportionate advantages later on. Which means, more features, better encoding, different clustering algorithms, and better tuning.
Cluster Analysis
Clusters reveal distinct user personas. The following table summarizes attributes and preferences:
| Cluster | DPI | Tier | Gender | Price | Preference Categories (ordered by priority) |
|---|---|---|---|---|---|
| 0 | High | Mix | Male | Mix | Finance, Productivity, Entertainment |
| 1 | High | T1/T3 | Male | Mix | Shopping, Finance, Business, Social |
| 2 | High | Mix | Male | Middle | Finance, Social |
| 3 | Very Low | Mix | Mix | Low | Finance, Social, Entertainment |
| 4 | Low | Mix | Mix | Middle | Social, Entertainment, Finance, Shopping |
| 5 | Very High | Mix | Mix | High | Shopping, Finance, Entertainment, Productivity |
Interaction Patterns
Interaction scores can be based on various engagement metrics, such as dwell time, clicks, likes, shares, or any other relevant user actions.
Calculate interaction scores for users within each cluster, aggregate them, and visualize the data to represent cluster-content category relationships.

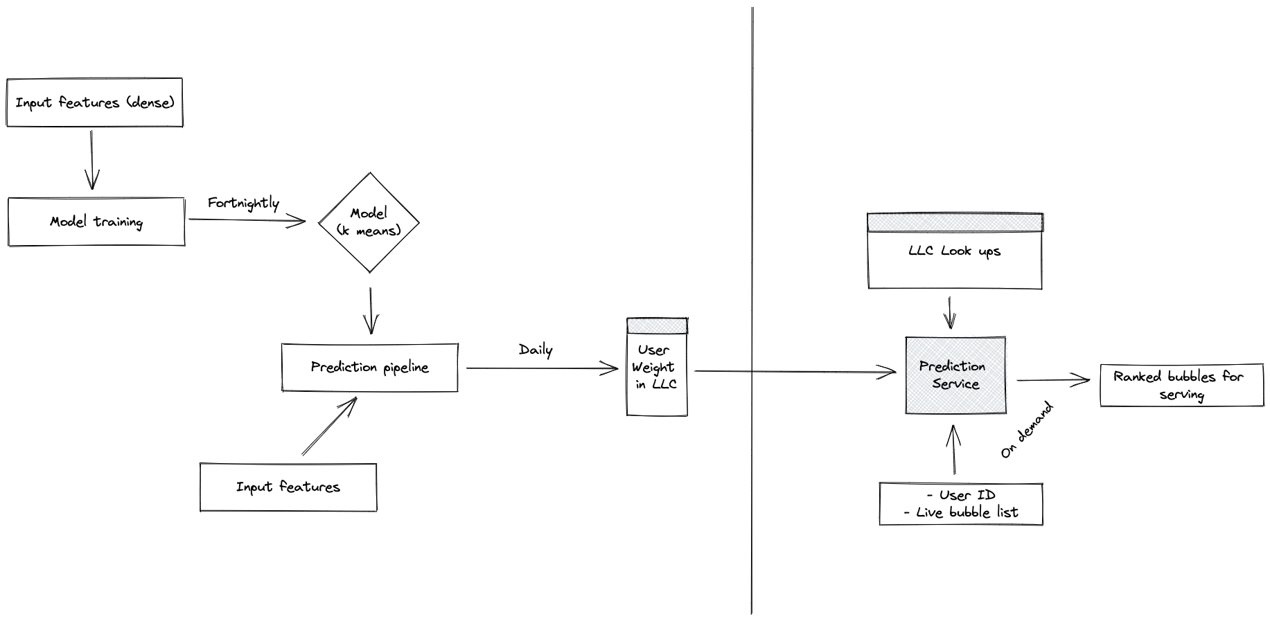
Step 2 - Taking It Online
To rank content for sparse users:
- Find the cluster that a sparse user, A, belongs to; call it X.
- Find the dense user at the center of the cluster, c(X) = Y.
- Find the predictions we are going to send for the dense user, P(Y).
- Send these predictions to the sparse user, P(A) -> P(Y).
This approach uses real-time predictions, caching dense user weights for efficiency. We used a multi-armed bandit (MAB) model to provide exploration and discovery within recommendations. The MAB would identify the slots, here categories, that we need. And depending on the category, we would fill the slots with either popularity or recency-ranked items of that category. Some categories work better with recency, like news, while others work better with popularity, like fashion - this we had established as part of a prior analysis.
Step 3 - Experimentation and Iterations
Performance Metrics
- Time Spent: 11.68% increase compared to the baseline.
- Reward Rate: 4.5% increase compared to the baseline.
Performance on Cold Users
- Cold Users: 18.38% increase in time spent and 5.76% increase in reward rate.
These results of the A/B experiment highlight the effectiveness of the clustering-based recommendation system in improving engagement. Further iterations and optimizations are ongoing, but the initial success is promising.
So we wrote a paper about it :)
For a detailed study, refer to the paper.
For more information, contact me or Ritika.
Cheers.